


8.3 Asymptotic formulae
8.3.1 Asymptotic form of the MLE
So far, we have discussed how to extract meaningful statistical results from HEP experiments by making extensive use of pseudodata / toy experiments to estimate the sampling distributions of profile-likelihood-ratio-based test statistics. While this worked nicely for our simple counting experiment, generating a sufficiently large number of toys can quickly become computationally intractable for the more complex searches (and statistical combinations of searches) that are increasingly prevalent at the LHC, containing at times up to thousands of bins and nuisance parameters. This and the following section discuss a way to approximate these sampling distributions without the need for pseudodata. This was introduced in the famous “CCGV” paper [301] in 2011 and has since become the de-facto procedure at the LHC.
As hinted at previously, such as in Figures 8.6 and 8.12, the distributions and (where, in general, ) have similar forms regardless of the nuisance parameters (or sometimes even the POIs). This is not a coincidence: we will now derive their “asymptotic” — i.e., in the large sample limit — forms, starting first with the asymptotic form of the maximum likelihood estimator (MLE).
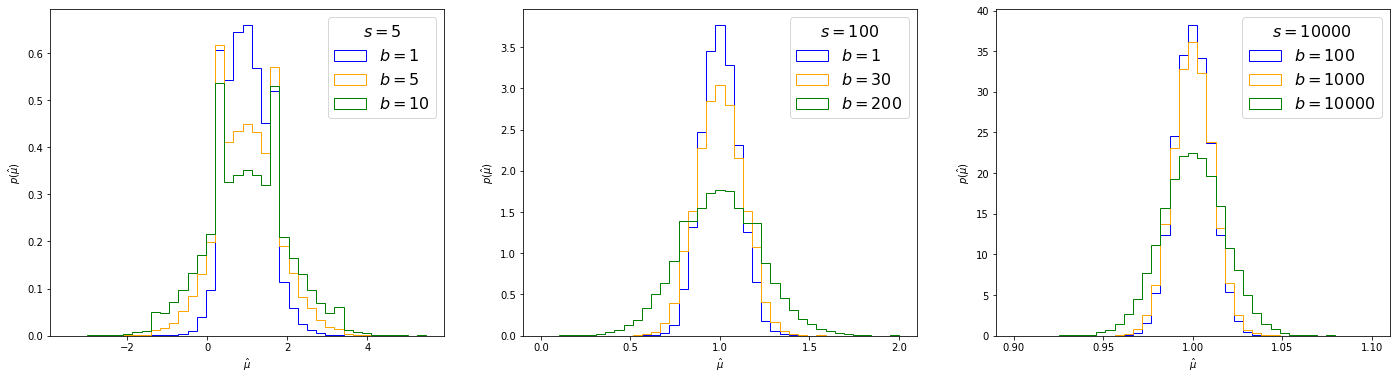
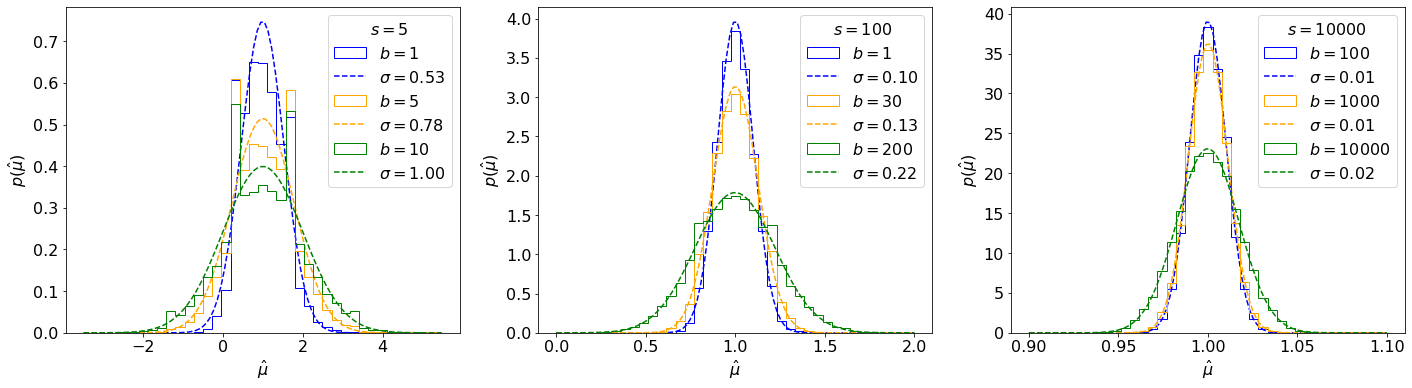
It is important to remember that the MLE of is a random variable with its own probability distribution. We can estimate it as always by sampling toys, shown in Figure 8.20 for our counting experiment (Eq. 8.2.3). One can observe that follows a Gaussian distribution as the number of events increases, and indeed this becomes clear if we try to fit one to the histograms (Figure 8.21). We will now show this to be true generally, deriving the analytic distribution in Sections 8.3.1.—8.3.1., and discussing the results and the important concept of the Asimov dataset for numerical estimation in Sections 8.3.1. and 8.3.1., respectively.
Statistics background
We first provide a lightning review of some necessary statistics concepts and results.
Definition 8.3.1. Let the negative log-likelihood (NLL) . The derivative of the NLL is called the score . It has a number of useful properties: 5
- 1.
- Its expectation value at .
- 2.
- Its variance .
Note that the expectation value here means an average over observations which are distributed according to a particular , which here we’re calling the “true” : .
Definition 8.3.2. is called the Fisher information. It quantifies the information our data contains about and importantly, as we’ll see, it (approximately) represents the inverse of the variance of . More generally, for multiple parameters,
|
| (8.3.1) |
is the Fisher information matrix. It is also commonly called the covariance matrix.
Theorem 8.3.1. Putting this together, by the central limit theorem [306], this means follows a normal distribution with mean and variance , up to terms of order :
|
| (8.3.2) |
where represents the data sample size.
The Fisher information
For our simple counting experiment, the Fisher information matrix can be found by taking second derivatives of the NLL (Eq. 8.2.5). The term, for example, is:
|
| (8.3.3) |
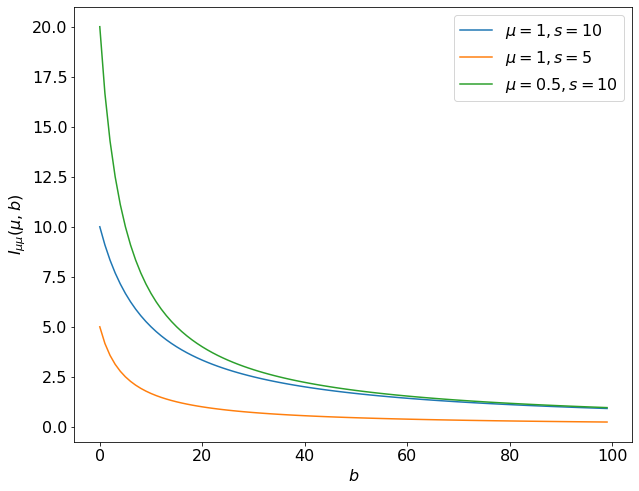
In the last step we use the fact that under true , , is . For the remainder of this section, will always be evaluated at the true values of the parameters,6 so this can be simplified to . This is plotted in Figure 8.22, where we can the Fisher information captures the fact that as increases, we lose sensitivity to — or information about — .
For completeness (and since we’ll need it below), the full Fisher information matrix for our problem, repeating the steps in Eq. 8.3.3, is:
|
| (8.3.4) |
Derivation
We now have enough background to derive the asymptotic form of the MLE. We do this for the 1D case by Taylor-expanding the score of , - which we know to be - around :
where we plugged in the distribution of from Eq. 8.3.2, claimed asymptotically equals its expectation value by the law of large numbers [307], and are ignoring the term.7
For multiple parameters, is a matrix so the variance generalized to the matrix inverse:
|
| (8.3.7) |
Result
Thus, we see that asymptotically follows a normal distribution around the true value, , with a variance , up to terms. Intuitively, from the definition of the Fisher information , we can interpret this as saying that the more information we have about from the data, the lower the variance should be on .
Continuing with our counting experiment from Section 8.2.1., inverting from Eq. 8.3.4 gives us
|
| (8.3.8) |
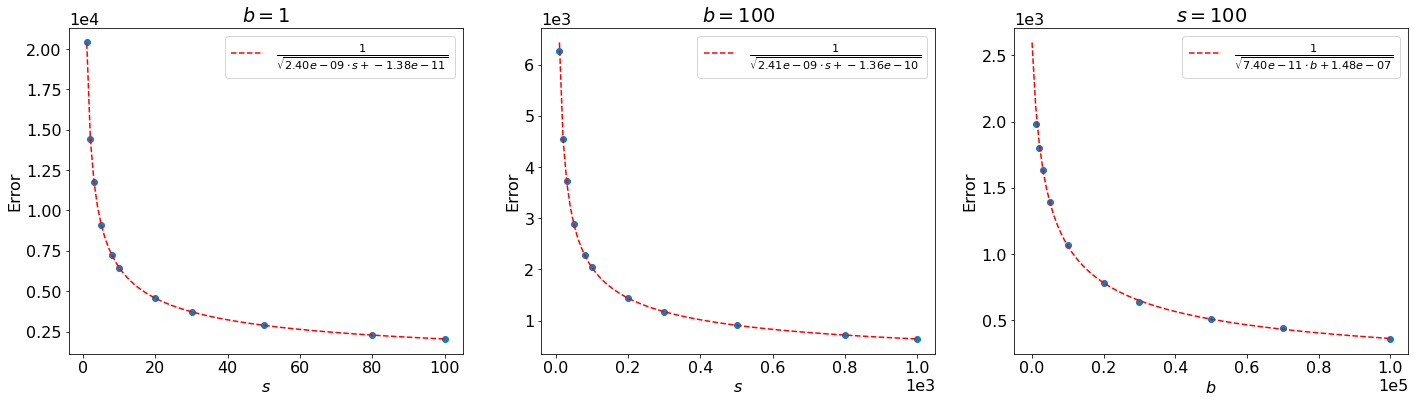
Note that, as we might expect, this scales as , which is the uncertainty of our Poisson nuisance parameter — showing mathematically why we want to keep uncertainties on nuisance parameters as low as possible. This is compared to the toy-based distributions from Section 8.3.1 in Figure 8.23 this time varying the true signal strength as well, where we can observe that this matches very well for large , while for small values there are some discrete differences.
We can also check the total per-bin errors between the asymptotic form and the toy-based distributions directly, as shown in Figure 8.24 (for only). Indeed, this confirms that the error scales as and , as claimed above.
Numerical estimation and the Asimov dataset
In this section, because of the simplicity of our data model, we were able to derive the Fisher information and, hence, the asymptotic form of analytically. In general, this is not possible and we typically have to minimize , find its second derivatives, and solve Eq. 8.3.3 etc. numerically instead.
However, when calculating the Fisher information, how do we deal with the expectation value over the observed data ( in our case)? Naively, this would require averaging over a bunch of generated toy values again, which defeats the purpose of using the asymptotic form of !
Instead, we can switch the order of operations in Eq. 8.3.3,8 rewriting it as:
|
| (8.3.9) |
Importantly, this says we can find by simply evaluating the likelihood for a dataset of observations equal to their expectation values under instead of averaging over the distribution of observations and then getting its second derivatives.
Definition 8.3.3. Such a dataset is called the Asimov dataset, and is referred to as the “Asimov likelihood”.9
8.3.2 Asymptotic form of the profile likelihood ratio
We can now proceed to derive the asymptotic form of the sampling distribution of the profile likelihood ratio test statistic , under a “true” signal strength of . This asymptotic form is extremely useful for simplifying the computation of (expected) significances, limits, and intervals; indeed, standard procedure at the LHC is to use it in lieu of toy-based, empirical distributions for .
Asymptotic form of the profile likelihood ratio
We start with deriving the asymptotic form of the profile likelihood ratio test statistic (Eq. 8.2.7) by following a similar procedure to Section 8.3.1. — and using the results therein — of Taylor expanding around its minimum at :10
Here, just like in Eq. 8.3.6, we use the law of large numbers in Line 8.3.14 and take to asymptotically equal its expectation value under the true parameter values : . We then in Line 8.3.15 also use the fact that MLEs are generally unbiased estimators of the true parameter values in the large sample limit to say . Finally, in the last step, we use the asymptotic form of the MLE (Eq. 8.3.7).
Asymptotic form of
Now that we have an expression for , we can consider its sampling distribution. With a simple change of variables, the form of should hopefully be evident: recognizing that and are simply constants, while we know is distributed as a Gaussian centered around with variance , let’s define , so that
For the special case of , we can see that is simply the square of a standard normal random variable, which is the definition of the well-known distribution with degrees of freedom (DoF):
|
| (8.3.20) |
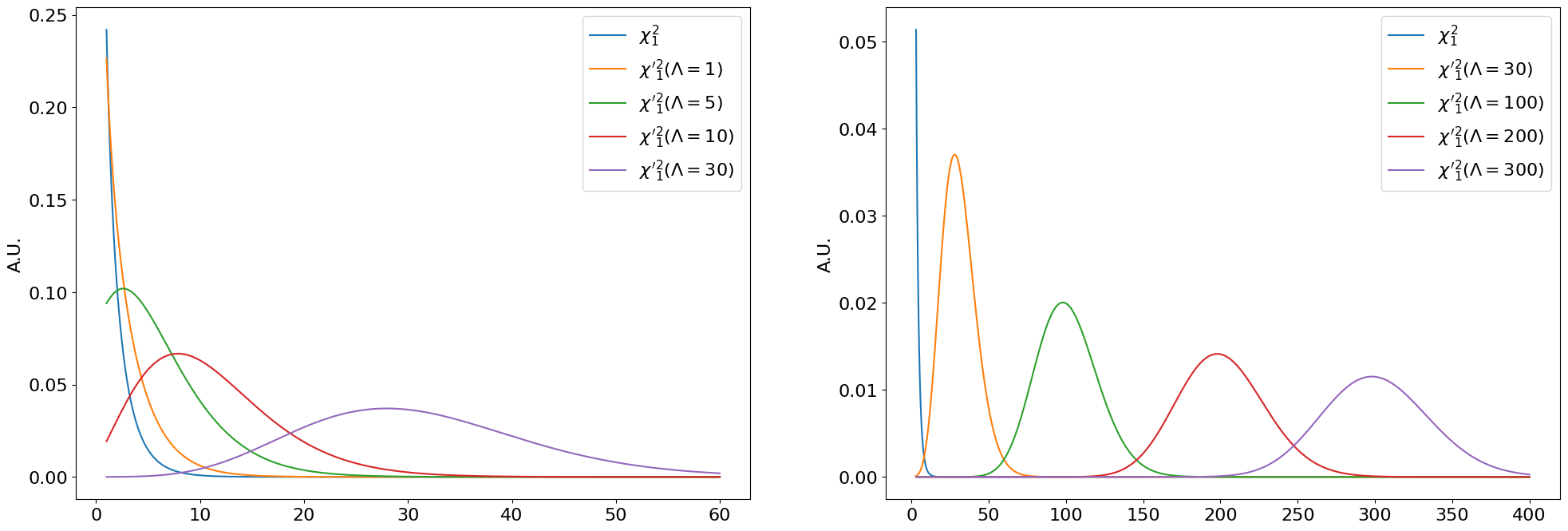
In the general case where may not , is the square of random variable with unit variance but non-zero mean. This is distributed as the similar, but perhaps less well-known, non-central chi-squared , again with 1 DoF, and with a “non-centrality parameter”
The “central” vs. non-central chi-squared distributions are visualized in Figure 8.25 for . We can see that simply shifts towards the right as increases (at it is a regular central ). As , becomes more and more like a normal distribution with mean .11
By extending the derivation in Eq. 8.3.17 to multiple POIs, one can find the simple generalization to multiple POIs :
|
| (8.3.23) |
where the DoF are equal the number of POIs , and
|
| (8.3.24) |
where is restricted only to the components corresponding to the POIs.
Estimating
The critical remaining step to understanding the asymptotic distribution of is estimating to find the non-centrality parameter in Eq. 8.3.21. We now discuss two methods to do this.
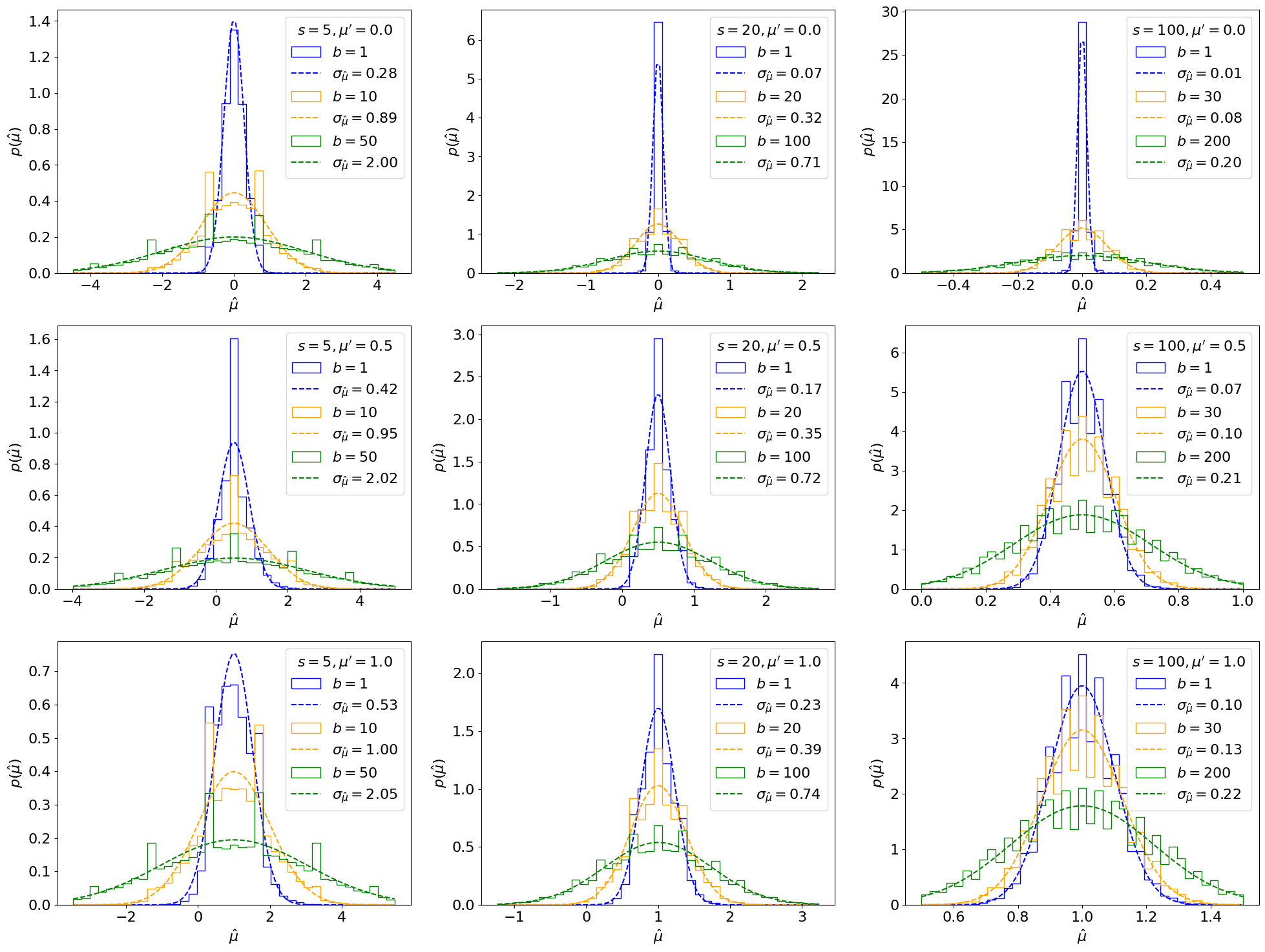
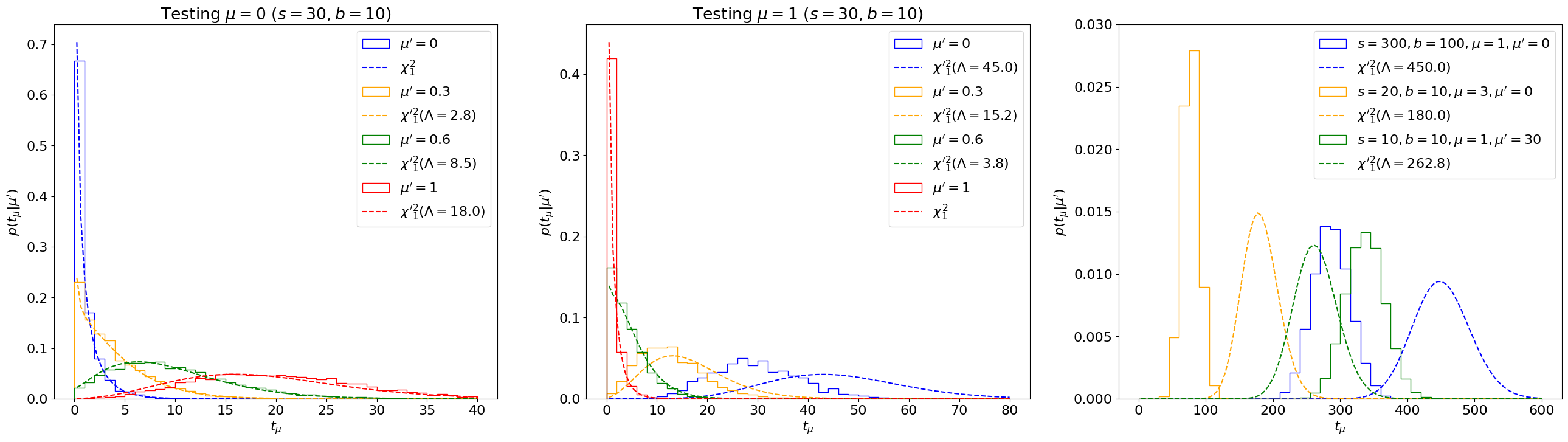
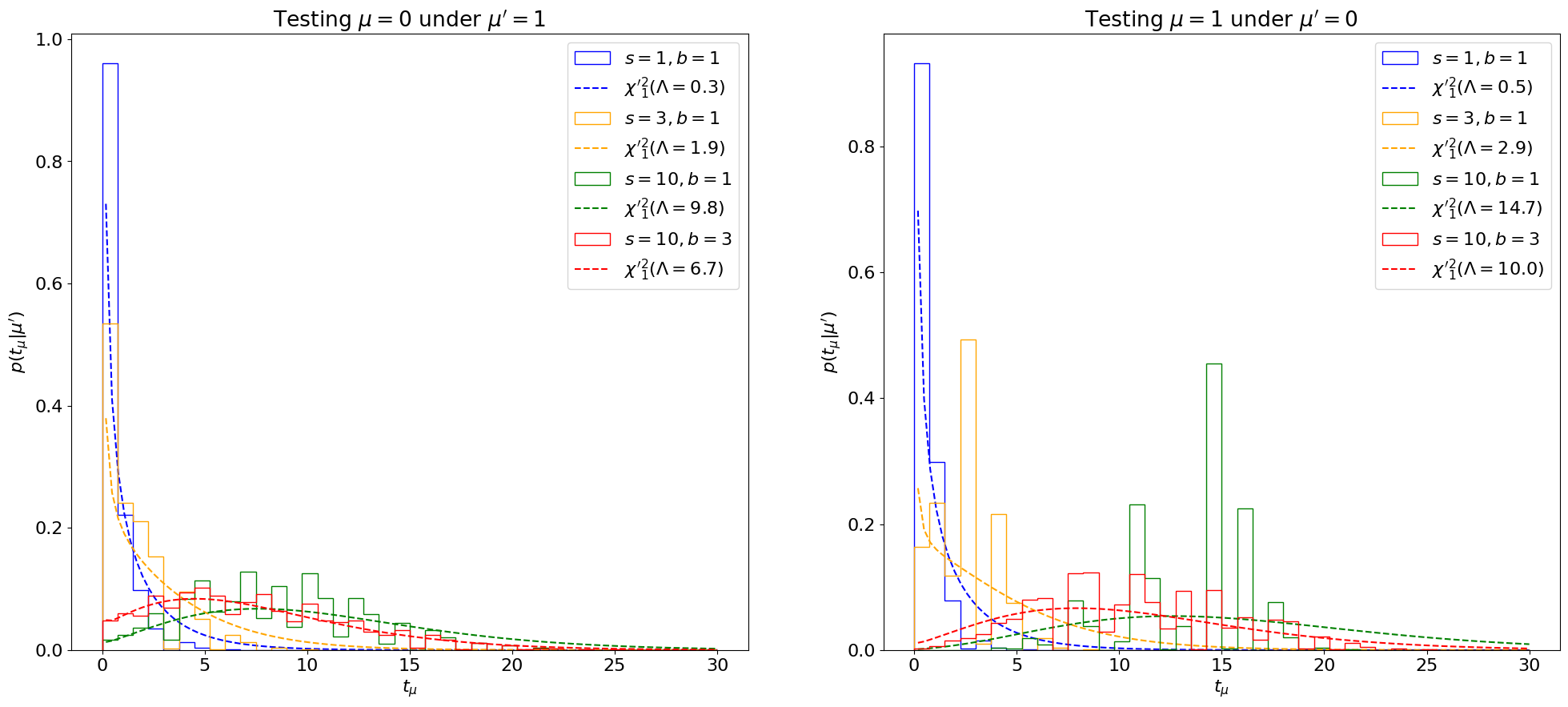
Method 1: Inverting the Fisher information / covariance matrix The first method is simply using as in Section 8.3.1.12 This is shown in Figure 8.26 for our counting experiment, using the analytic form for from Eq. 8.3.8. We can see that this asymptotic approximation agrees well with the true distribution for some range of parameters, but can deviate significantly for others, as highlighted especially in the right plot.
Interlude on Asimov dataset While we are able to find the analytic form for easily for our simple counting experiment, in general it has to be calculated numerically. As introduced in Section 8.3.1., to handle the expectation value under in Eq. 8.3.1, we can make use of the Asimov dataset, where the observations , are taken to be their expectation values under , simplifying the calculation of to Eq. 8.3.9.
Explicitly, for our counting experiment (Eq. 8.2.3), the Asimov observations are simply
We’ll now consider a second powerful use of the Asimov dataset to estimate .
Method 2: The “Asimov sigma” estimate Putting together Eqs. 8.2.10 and 8.3.26, we can derive a nice property of the Asimov dataset: the MLEs , equal the true values , :
Thus, evaluated for the Asimov dataset is exactly the non-centrality parameter that we are after!
|
| (8.3.29) |
While, not strictly necessary to obtain the asymptotic form for , we can also invert this to estimate , as
|
| (8.3.30) |
where is known as the “Asimov sigma”.
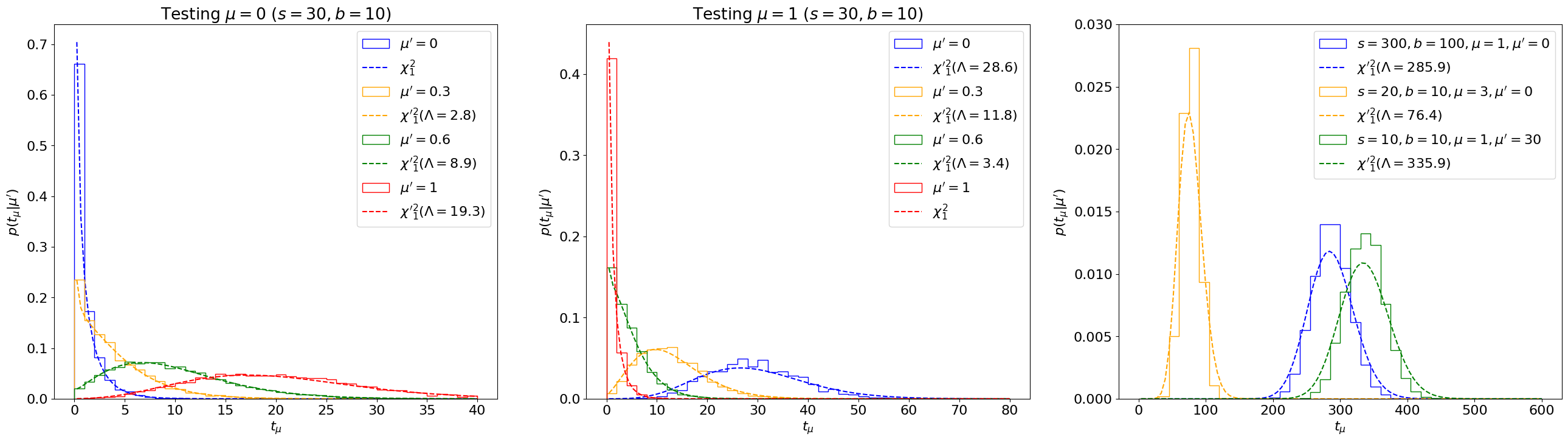
The asymptotic distributions using are plotted in Figure 8.27. We see that this estimate matches the sampling distributions very well, even for cases where the covariance-matrix-estimate failed! Indeed, this is why estimating is the standard in LHC analyses, and that is the method we’ll employ going forward.
Reference [301] conjectures that this is because the Fisher-information-approach is restricted only to estimating the second-order term of Eq. 8.3.17, while with we’re matching the shape of the likelihood at the minimum which may be able capture some of the higher order terms as well.
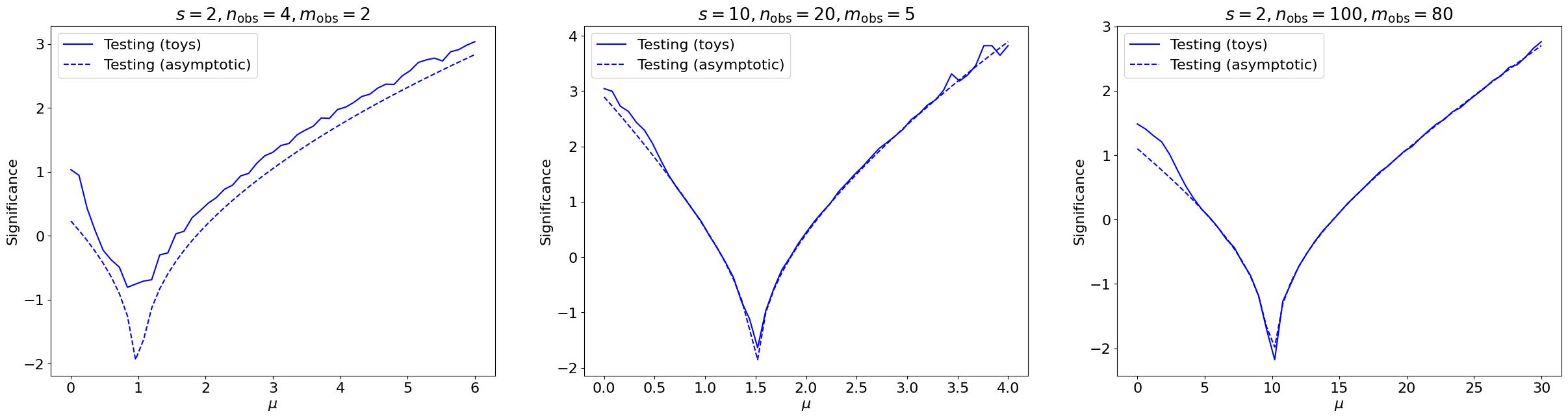
Despite the pervasive use of the asymptotic formula at the LHC, it’s important to remember that it’s an approximation, only valid for large statistics. Figure 8.28 shows it breaking down for below.
The PDF and CDF
The probability distribution function (PDF) for a distribution can be found in e.g. Ref. [309] for :
|
| (8.3.31) |
where is the PDF of a standard normal distribution. For , this simplifies to:
|
| (8.3.32) |
The cumulative distribution function (CDF) for is:
|
| (8.3.33) |
where is the CDF of the standard normal distribution. For , again this simplifies to:
|
| (8.3.34) |
From Eq. 8.2.14, we know the -value of the observed under a signal hypothesis of is
|
| (8.3.35) |
with an associated significance
|
| (8.3.36) |
Application to hypothesis testing
Let’s see how well this approximation agrees with the toy-based -value we found in Example 8.2.1. For the same counting experiment example, where we expect and observe , , we found the -value for testing the hypothesis (and the associated significance ). Calculating for this example and plugging it into the asymptotic approximation from Eq. 8.3.35 gives:13
We see that it agrees exactly!
The agreement more generally, with varying , is plotted in Figure 8.29. We observe generally strong agreement, except for low where, as expected, the asymptotic approximation breaks down.
Summary
We have been able to find the asymptotic form for the profile-likelihood-ratio test statistic , which is distributed as a non-central chi-squared () distribution. We discussed two methods for finding the non-centrality parameter , out of which the Asimov sigma estimation generally performed better. Finally, the asymptotic formulae were applied to simple examples of hypothesis testing to check the agreement with toy-based significances. These asymptotic formulae can be extended to the alternative test statistics for positive signals and upper-limit-setting , as in Ref. [301], to simplify the calculation of both observed and expected significances, limits, and intervals.
With that, we conclude the overview of the statistical interpretation of LHC results. We will see practical applications of these concepts to searches in the high energy Higgs sector in Part V.
5See derivations in e.g. Ref. [305].
6The reason for this is discussed shortly in Section 8.3.1..
7For a more rigorous derivation, see e.g. Ref. [308].
8We are able to do this because, as we saw above, the score is linear in for Poisson likelihoods.
9The Asimov dataset is named after Isaac Asimov, the popular science fiction author, whose book Franchise is about a supercomputer choosing a single person as the sole voter in the U.S. elections, because they can represent the entire population.
10Note: this is not a rigorous derivation; it’s just a way to motivate the final result, which is taken from Ref. [301]. (If you know of a better way, let me know!)
11More information can be found in e.g. Ref. [309].
12More generally, we’d need for Eq. 8.3.24.
13Note that we’re using here, not the alternative test statistic ; however, in this case since , they are equivalent.