


C.1 MPGANs
C.1.1 Point Cloud Generative Models
ShapeNet Point Clouds
A number of successful generative models exploit a key inductive bias of ShapeNet-based clouds: that the individual distributions of sampled points conditioned on a particular object are identical and independent (the i.i.d assumption). This assumption allows for hierarchical generative frameworks, such as Point-Cloud-GAN (PCGAN) [289], which uses two networks: one to generate a latent object-level representation, and a second to sample independent points given such a representation. The PointFlow [290] and Discrete PointFlow [291] models use a similar idea of sampling independently points conditioned on a learned latent representation of the shape, but with a variational autoencoder (VAE) framework and using normalizing flows for transforming the sampled points.
This hierarchical-sampling approach is appealing for ShapeNet clouds, however, as discussed in Chapter 7.3.3 the key i.i.d. assumption is not applicable to jets with their highly correlated particle constituents. In fact, in contrast to ShapeNet objects which have a structure independent of the particular sampled cloud, jets are entirely defined by the distribution of their constituents.
Another model, ShapeGF [292], uses an approach of again sampling points independently from a prior distribution, but transforming them to areas of high density via gradient ascent, maximizing a learned log-density concentrated on an object’s surface. This approach suffers as well from the i.i.d. assumption in the context of jets, and additionally, unlike for ShapeNet point clouds, there is no such high-density region in momentum-space where particles tend to be concentrated, so learning and maximizing a log-density is not straightforward.
To support our overall claim of the inviability of the i.i.d. assumption for particle clouds, we train a PCGAN model on JetNet and show the produced feature distributions in Figure C.1. We can see that, as expected, while this network is partially reproducing the particle feature distributions, it is entirely unable to learn the jet-level structure in particle clouds.
Molecular Point Clouds
3D molecules are another common point-cloud-style data structure, and there have been developments in generative models in this area as well. Kohler et al. [293] introduce physics-motivated normalizing flows equivariant to rotations around the center of mass, i.e. the SO(N) symmetries, for generating point clouds. This is appealing as normalizing flows give access to the explicit likelihood of generated samples, and having an architecture equivariant to physical symmetries such as 3D rotations can improve the generalizability and interpretability of the model. Since jets are relativistic, however, we require an architecture equivariant to the non-compact SO(3, 1) Lorentz group, to which this model has not been generalized yet. Simm et al. [294] present a reinforcement-learning-based approach for generating 3D molecules, using an agent to iteratively add atoms to a molecule and defining the reward function as the energy difference between the new molecule and the old with the new atom at the origin. This reward function is not directly applicable to jets. where particle distributions are based on the QCD dynamics rather than on minimizing the total energy. Finally, Gebauer et al. [295] introduce G-SchNet, an autoregressive model for producing molecules represented as point clouds, iteratively adding one atom at a time based on the existing molecule. Their iterative procedure however was proposed for point clouds of at most nine atoms, and does not scale well in terms of time to larger clouds.
Overall, all the models discussed heavily incorporate inductive biases which are specific to their respective datasets and don’t apply to JetNet. However, they are extremely interesting approaches nonetheless, and adapting them with jet-motivated biases should certainly be explored in future work. Indeed, a significant contribution of our work is publishing a dataset which can facilitate and hopes to motivate such development.
C.1.2 Training and Implementation Details
PyTorch code and trained parameters for models in Table 10.2 are provided in the MPGAN repository [331]. Models were trained and hyperparameters optimized on clusters of NVIDIA GeForce RTX 2080 Ti, Tesla V100, and A100 GPUs.
MPGAN
We use the least squares loss function [335] and the RMSProp optimizer with a two time-scale update rule [324] with a learning rate (LR) for the discriminator three times greater than that of the generator. The absolute rate differed per jet type. We use LeakyReLU activations (with negative slope coefficient 0.2) after all MLP layers except for the final generator and discriminator outputs where tanh and sigmoid activations respectively are applied. We attempted discriminator regularization to alleviate mode collapse via dropout [218], batch normalization [219], a gradient penalty [449], spectral normalization [450], adaptive competitive gradient descent [451] and data augmentation of real and generated graphs before the discriminator [452–454]. Apart from dropout (with fraction ), none of these demonstrated significant improvement with respect to mode dropping or cloud quality.
We use a generator LR of and train for 2000 epochs for gluon jets, and 2000 epochs for top quark jets, and and 2500 epochs for light quark jets. We use a batch size of 256 for all jets.
rGAN, GraphCNNGAN, TreeGAN, and PointNet-Mix
For rGAN and GraphCNNGAN we train two variants: (1) using the original architecture hyperparameters in Refs. [296, 297] for the 2048-node point clouds, and (2) using hyperparameters scaled down to 30-node clouds—specifically: a 32 dimensional latent space, followed by layers of 64, 128, and 90 nodes for r-GAN, or followed by two graph convolutional layers with node features sizes of 32 and 24 respectively for GraphCNN-GAN. The scaled-down variant performed better for both models, and its scores are the ones reported in Table 10.2. For TreeGAN, starting from single vertex—in analogy with a jet originating from a single particle—we use five layers of up-sampling and ancestor-descendant message passing, with a scale-factor of two in each and node features per layer of 96, 64, 64, 64, and 64 respectively. LRs, batch sizes, loss functions, gradient penalties, optimizers, ratios of critic to generator updates, activations, and number of epochs are the same as in the original paper and code. We use the architecture defined in [300] for the PointNet-Mix discriminator.
FPND
Apart from the number of input particle features (three in our case, excluding the mask feature), we use the original ParticleNet architecture in Ref. [230]. We find training with the Adam optimizer, LR , for 30 epochs outperformed the original recommendations on our dataset. Activations after the first fully connected layer, pre-ReLU, are used for the FPND measurement.
PCGAN
We use the original PCGAN implementation for the sampling networks and training, with a 256-dimensional latent object representation. For the latent code GAN we use a 3 layer fully connected network for both the generator, with an input size of 128 and intermediate layer sizes of 256 and 512, and discriminator, with intermediate layer sizes of 512 and 256, trained using the Wasserstein-GAN [455] loss with a gradient penalty.
C.1.3 Masking Strategies
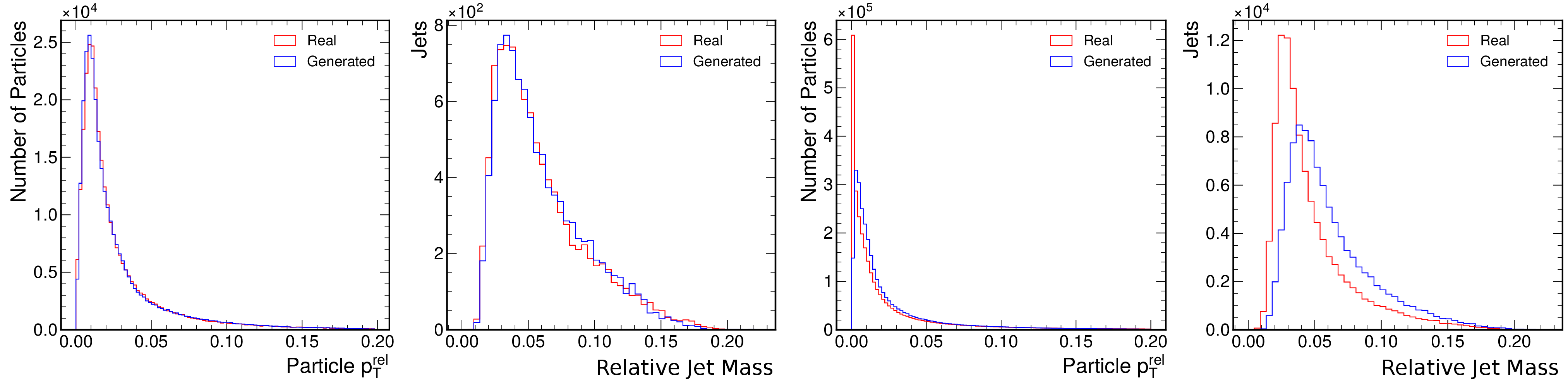
In the JetNet dataset used for training MPGAN, jets with fewer than 30 particles are zero-padded to fill the 30-particle point cloud. Such zero-padded particles pose a problem for the generator, which is not able to learn this sharp discontinuity in the jet constituents (Figure C.2).
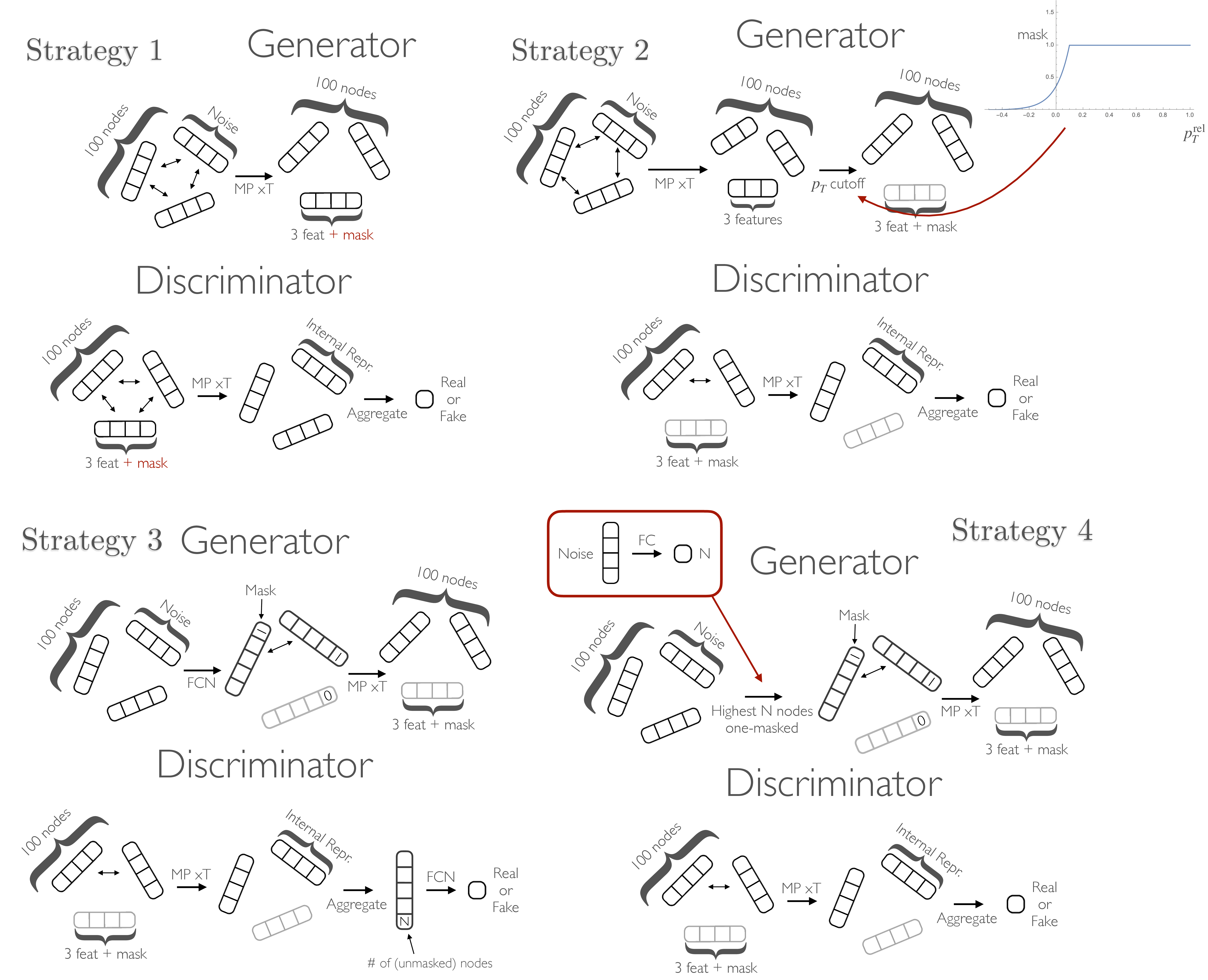
To counter this issue, we experiment with five masking strategies, out of which the one described in Section 10.1.2 was most successful. The four alternatives, which all involve the generator learning the mask without any external input, are shown in Figure C.3.
Strategy 1 treats the mask homogeneously as an extra feature to learn. A variation of this weights the nodes in the discriminator the mask. In strategy 2, a mask is calculated for each generated particle as a function of its , based on an empirical minimum cutoff in the dataset. In particular, both a Heaviside-step-function and a continuous mask function as in the figure are tested. The standard MP discriminator, as described in Section 10.1.2, is used. Strategy 3 sees the generator applying an FC layer per particle in the initial cloud to learn their respective masks, with both the MP discriminator, as well as a variant with the number of unmasked nodes in the clouds added as an extra feature to the FC layer. In strategies 1 and 3 we test both binary and continuous masks. Finally, in strategy 4, we train an auxiliary network to choose a number of particles to mask (as opposed to sampling from the real distribution), which is then passed into the standard MP generator.
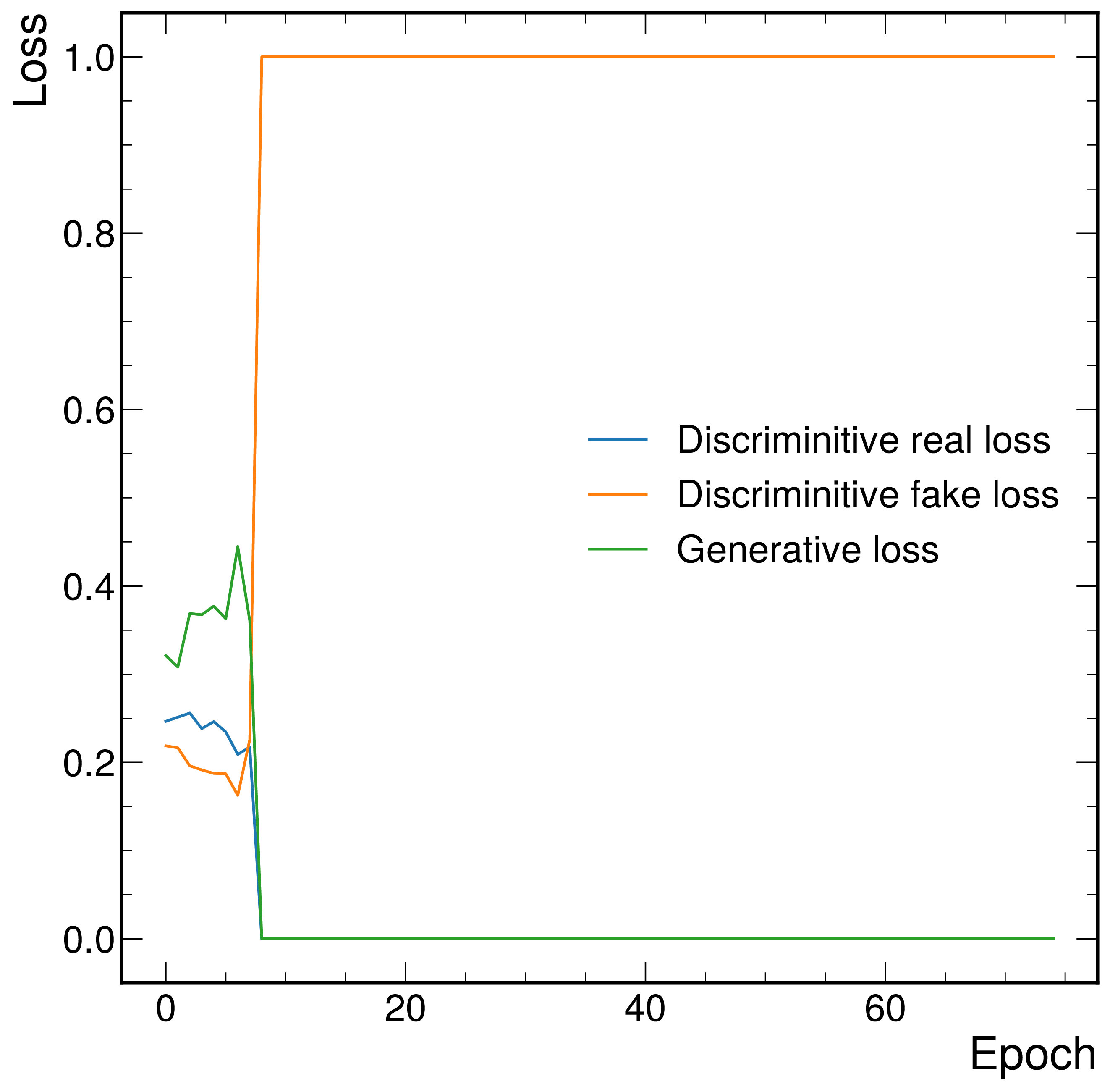
We find that all such strategies are unable to produce accurate light quark jets, and in fact trainings for each diverge in the fashion depicted in Figure C.4, even using each discriminator regularization method mentioned in Appendix C.1.2). We conclude that learning the number of particles to produce is a significant challenge for a generator network, but is a relatively simple feature with which to discriminate between real and fake jets. To equalize this we use the strategy in Section 10.1.2 where the number of particles to produce is sampled directly from the real distribution, removing the burden of learning this distribution from the generator network.