


E.1 Model details
E.1.1 LGAE
For both the encoder and decoder, we choose LMP layers. The multiplicity per node in each LMP layer has been optimized to be
|
| (E.1.1) |
for the encoder and
|
| (E.1.2) |
for the decoder, the components in the vector on the right-hand side are the multiplicity in each of the four LMP layers per network, and the multiplicity per layer is the same for all representations. After each CG decomposition, we truncate irreps of dimensions higher than for tractable computations, i.e., after each LMP operation we are left with only scalar and vector representations per node. Empirically, we did not find such a truncation to affect the performance of the model. This means that the LMP layers in the LGAE are similar in practice to those of LorentzNet, which uses only scalar and vector representations throughout, but are more general as higher dimensional representations are involved in the intermediate steps before truncation.
The differentiable mapping in Eq. 16.2.1 is chosen to be the Lorentzian bell function as in Ref. [54]. For all models, the latent space contains only complex Lorentz scalar, as we found increasing the number of scalars beyond one did not improve the performance in either reconstruction or anomaly detection. Empirically, the reconstruction performance increased with more latent vectors, as one might expect, while anomaly detection performance generally worsened from adding more than two latent vectors.
E.1.2 GNNAE
The GNNAE is constructed from fully-connected MPNNs. The update rule in the -th MPNN layer is based on MPGAN’s (Section 10.1), and given by
where is the node embedding of node at -th iteration, is any distance function (Euclidean norm in our case), is the message for updating node embedding in node , and are any learnable mapping at the current MP layer. A diagram for an MPNN layer is shown in Figure E.1. The overall architecture is similar to that in Figure 16.1, with the LMP replaced by the MPNN. The code for the GNNAE model can be found in the Ref. [456].
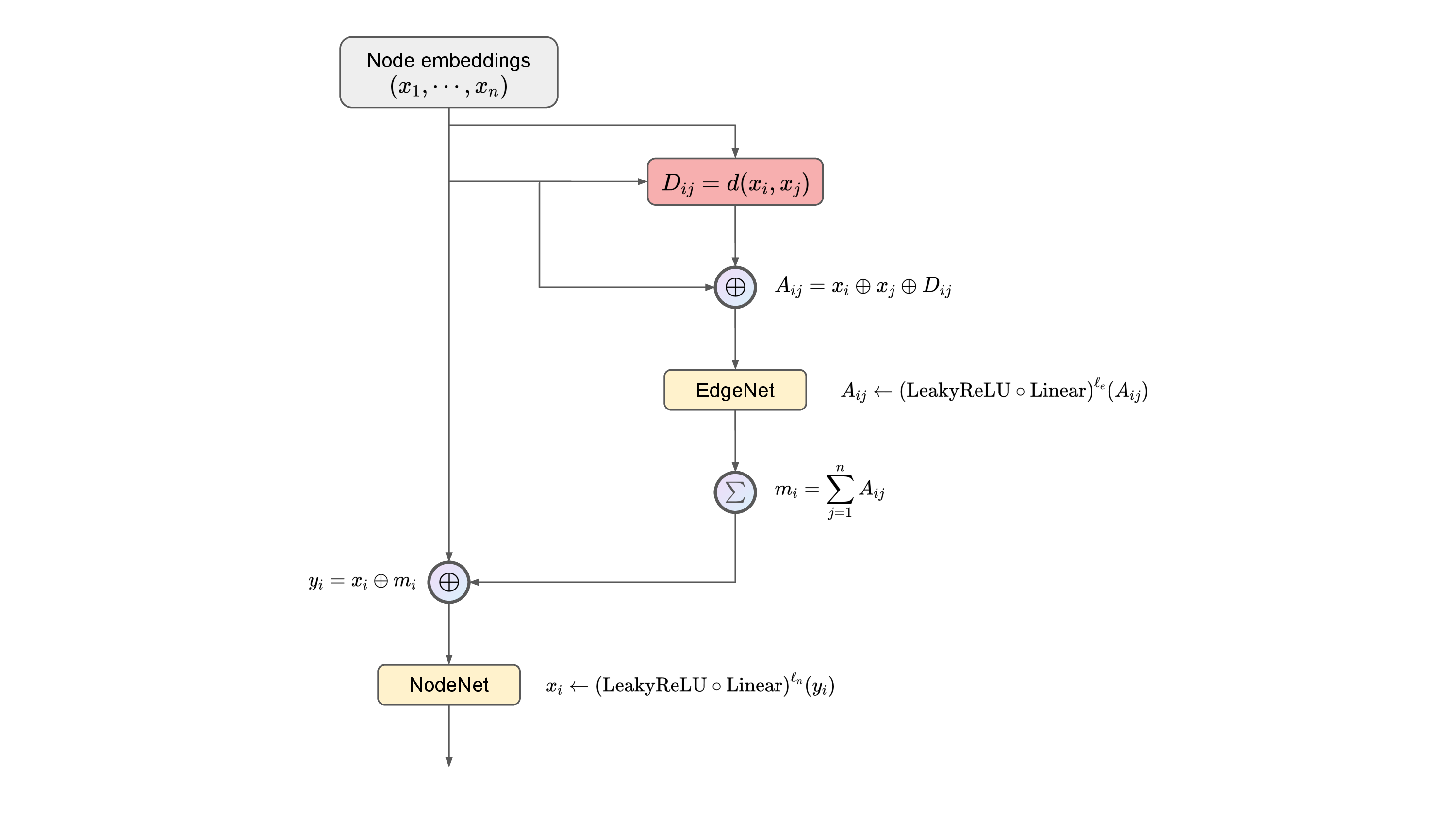
For both the encoder and decoder, there are MPNN layers. The learnable functions in each layer are optimized to be
|
| (E.1.5) |
| (E.1.6) |
| (E.1.7) |
where is the LeakyReLU function. Depending on the aggregation layer, the value of in and the final aggregation layer is different. For GNNAE-JL encoders, , where is the latent space, and is the number of nodes in the graph. Then, mean aggregation is done across the graph. For GNNAE-PL encoders, , where is the node dimension in the latent space. In the GNNAE-JL decoder, the input layer is a linear layer that recovers the particle cloud structure similar to that in the LGAE.
E.1.3 CNNAE
The encoder is composed of two convolutional layers with kernel size , stride size , “same" padding, and output channels, each followed by a ReLU activation function. The aggregation layer into the latent space is a fully-connected linear layer. The decoder is composed of transposed convolution layers (also known as deconvolutional layers) with the same settings as the encoder. A softmax function is applied at the end so that the sum of all pixel values in an image is , as a property of the jet image representation. A 55-dimensional latent space is chosen so that the compression rate is for even comparisons with the LGAE and GNNAE models.